


通過分步驟看數據持久化過程:write -> refresh -> flush -> merge
write 過程
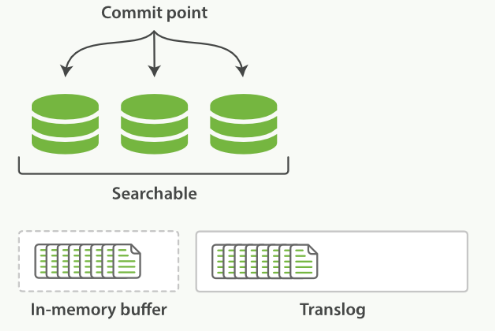
一個新文檔過來,會存儲在 in-memory buffer 內存緩存區中,順便會記錄 Translog(Elasticsearch 增加了一個 translog ,或者叫事務日志,在每一次對 Elasticsearch 進行操作時均進行了日志記錄)。
這時候數據還沒到 segment ,是搜不到這個新文檔的。數據只有被 refresh 后,才可以被搜索到。
refresh 過程
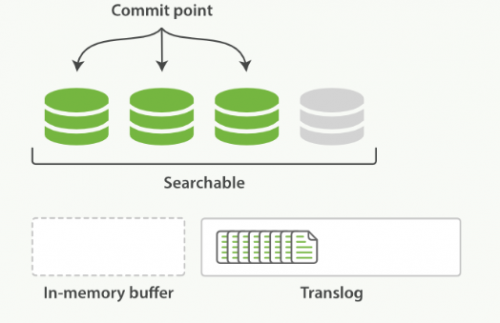
refresh 默認 1 秒鐘,執行一次上圖流程。ES 是支持修改這個值的,通過 index.refresh_interval 設置 refresh (沖刷)間隔時間。refresh 流程大致如下:
1.in-memory buffer 中的文檔寫入到新的 segment 中,但 segment 是存儲在文件系統的緩存中。此時文檔可以被搜索到
2.最后清空 in-memory buffer。注意: Translog 沒有被清空,為了將 segment 數據寫到磁盤
3.文檔經過 refresh 后, segment 暫時寫到文件系統緩存,這樣避免了性能 IO 操作,又可以使文檔搜索到。refresh 默認 1 秒執行一次,性能損耗太大。一般建議稍微延長這個 refresh 時間間隔,比如 5 s。因此,ES 其實就是準實時,達不到真正的實時。
flush 過程
每隔一段時間—例如 translog 變得越來越大—索引被刷新(flush);一個新的 translog 被創建,并且一個全量提交被執行
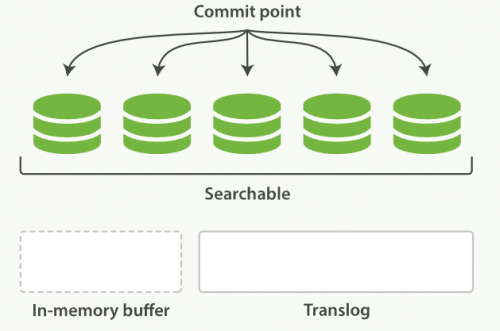
上個過程中 segment 在文件系統緩存中,會有意外故障文檔丟失。那么,為了保證文檔不會丟失,需要將文檔寫入磁盤。那么文檔從文件緩存寫入磁盤的過程就是 flush。寫入磁盤后,清空 translog。具體過程如下:
所有在內存緩沖區的文檔都被寫入一個新的段。緩沖區被清空。一個Commit Point被寫入硬盤。文件系統緩存通過 fsync 被刷新(flush)。老的 translog 被刪除。
merge 過程
由于自動刷新流程每秒會創建一個新的段 ,這樣會導致短時間內的段數量暴增。而段數目太多會帶來較大的麻煩。 每一個段都會消耗文件句柄、內存和cpu運行周期。更重要的是,每個搜索請求都必須輪流檢查每個段;所以段越多,搜索也就越慢。
Elasticsearch通過在后臺進行Merge Segment來解決這個問題。小的段被合并到大的段,然后這些大的段再被合并到更大的段。
當索引的時候,刷新(refresh)操作會創建新的段并將段打開以供搜索使用。合并進程選擇一小部分大小相似的段,并且在后臺將它們合并到更大的段中。這并不會中斷索引和搜索。
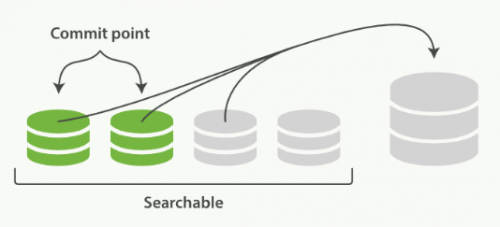
一旦合并結束,老的段被刪除:
新的段被刷新(flush)到了磁盤。 ** 寫入一個包含新段且排除舊的和較小的段的新提交點。新的段被打開用來搜索。老的段被刪除。

合并大的段需要消耗大量的I/O和CPU資源,如果任其發展會影響搜索性能。Elasticsearch在默認情況下會對合并流程進行資源限制,所以搜索仍然 有足夠的資源很好地執行。















 京公網安備 11010802030320號
京公網安備 11010802030320號